what kind of joins do you use to join large tables in oracle 11g
24
Optimization of Joins
Will you, won't yous, will you, won't you, will you join the dance?
Lewis Carroll
This chapter discusses how the Oracle optimizer executes SQL statements that contain joins, anti-joins, and semi-joins. Information technology likewise describes how the optimizer tin can utilize bitmap indexes to execute star queries, which join a fact table to multiple dimension tables. This chapter includes:
- Optimizing Bring together Statements
- Optimizing Anti-Joins and Semi-Joins
- Optimizing "Star" Queries
Optimizing Join Statements
To choose an execution plan for a join argument, the optimizer must make these interrelated decisions:
| access paths | As for simple statements, the optimizer must cull an admission path to retrieve data from each table in the join statement. (Run across "Choosing Access Paths".) |
| join operations | To join each pair of row sources, Oracle must perform one of these operations:
|
| join club | To execute a statement that joins more 2 tables, Oracle joins two of the tables, and then joins the resulting row source to the side by side table. This procedure is continued until all tables are joined into the result. |
Join Operations
The optimizer can use the post-obit operations to join ii row sources:
- Nested Loops Bring together
- Sort-Merge Join
- Cluster Bring together
- Hash Join
Nested Loops Join
To perform a nested loops join, Oracle follows these steps:
- The optimizer chooses one of the tables equally the outer table, or the driving table. The other table is called the inner table.
- For each row in the outer table, Oracle finds all rows in the inner table that satisfy the bring together status.
- Oracle combines the data in each pair of rows that satisfy the join status and returns the resulting rows.
Effigy 24-one shows the execution plan for this statement using a nested loops bring together:
SELECT * FROM emp, dept WHERE emp.deptno = dept.deptno;
Effigy 24-i Nested Loops Bring together
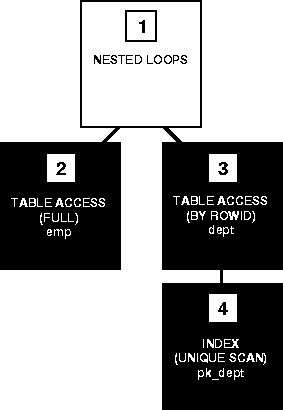
To execute this statement, Oracle performs these steps:
- Stride 2 accesses the outer table (EMP) with a full table scan.
- For each row returned by Step 2, Step 4 uses the EMP.DEPTNO value to perform a unique scan on the PK_DEPT alphabetize.
- Pace iii uses the rowid from Step iv to locate the matching row in the inner table (DEPT).
- Oracle combines each row returned by Footstep 2 with the matching row returned past Pace 4 and returns the result.
Sort-Merge Join
Oracle tin can just perform a sort-merge join for an equijoin. To perform a sort-merge bring together, Oracle follows these steps:
- Oracle sorts each row source to exist joined if they have not been sorted already by a previous operation. The rows are sorted on the values of the columns used in the join status.
- Oracle merges the 2 sources so that each pair of rows, one from each source, that contain matching values for the columns used in the bring together condition are combined and returned as the resulting row source.
Effigy 24-2 shows the execution plan for this statement using a sort-merge join:
SELECT * FROM emp, dept WHERE emp.deptno = dept.deptno;
Effigy 24-2 Sort-Merge Bring together
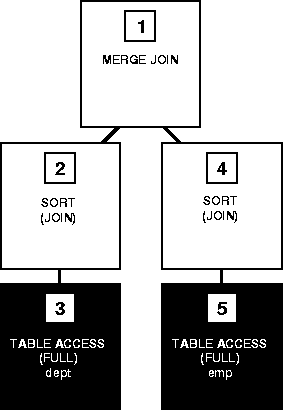
To execute this statement, Oracle performs these steps:
- Steps 3 and 5 perform full table scans of the EMP and DEPT tables.
- Steps 2 and 4 sort each row source separately.
- Step one merges the sources from Steps 2 and 4 together, combining each row from Pace ii with each matching row from Step 4, and returns the resulting row source.
Cluster Join
Oracle can perform a cluster join only for an equijoin that equates the cluster primal columns of two tables in the same cluster. In a cluster, rows from both tables with the aforementioned cluster fundamental values are stored in the same blocks, then Oracle only accesses those blocks.
Oracle8i Tuning provides guidelines for deciding which tables to cluster for best performance.
Figure 24-iii shows the execution plan for this statement in which the EMP and DEPT tables are stored together in the same cluster:
SELECT * FROM emp, dept WHERE emp.deptno = dept.deptno;
Figure 24-3 Cluster Bring together
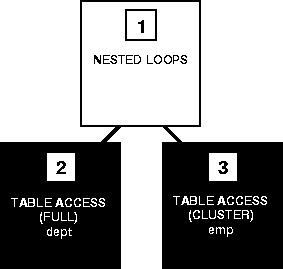
To execute this statement, Oracle performs these steps:
- Footstep two accesses the outer tabular array (DEPT) with a full table scan.
- For each row returned by Step two, Step 3 uses the DEPT.DEPTNO value to find the matching rows in the inner tabular array (EMP) with a cluster scan.
A cluster join is nothing more than a nested loops join involving two tables that are stored together in a cluster. Since each row from the DEPT table is stored in the same information blocks as the matching rows in the EMP table, Oracle can access matching rows well-nigh efficiently.
Hash Join
Oracle tin can only perform a hash join for an equijoin. Hash join is non available with dominion-based optimization. Y'all must enable hash bring together optimization, using the initialization parameter HASH_JOIN_ENABLED (which tin be fix with the ALTER SESSION command) or the USE_HASH hint.
To perform a hash join, Oracle follows these steps:
- Oracle performs a full table scan on each of the tables and splits each into as many partitions as possible based on the available retentiveness.
- Oracle builds a hash table from i of the partitions (if possible, Oracle will select a division that fits into bachelor memory). Oracle and so uses the respective sectionalisation in the other table to probe the hash tabular array. All partition pairs that do not fit into memory are placed onto disk.
- For each pair of partitions (ane from each table), Oracle uses the smaller ane to build a hash table and the larger ane to probe the hash table.
Figure 24-4 shows the execution plan for this statement using a hash bring together:
SELECT * FROM emp, dept WHERE emp.deptno = dept.deptno;
Effigy 24-4 Hash Bring together
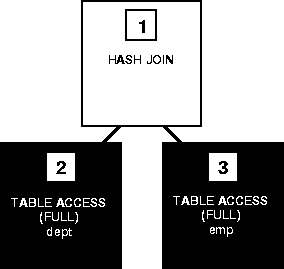
To execute this statement, Oracle performs these steps:
- Steps 2 and 3 perform full table scans of the EMP and DEPT tables.
- Step 1 builds a hash table out of the rows coming from Step 2 and probes it with each row coming from Pace iii.
The initialization parameter HASH_AREA_SIZE controls the amount of retention used for hash join operations and the initialization parameter HASH_MULTIBLOCK_IO_COUNT controls the number of blocks a hash join functioning should read and write concurrently.
See Oracle8i Tuning for more information most these initialization parameters and the USE_HASH hint.
Choosing Execution Plans for Join Statements
This section describes how the optimizer chooses an execution plan for a join statement:
- when using the price-based approach
- when using the rule-based arroyo
Notation these considerations that use to the cost-based and rule-based approaches:
- The optimizer first determines whether joining 2 or more than of the tables definitely results in a row source containing at nigh one row. The optimizer recognizes such situations based on UNIQUE and Main Fundamental constraints on the tables. If such a situation exists, the optimizer places these tables first in the join order. The optimizer then optimizes the bring together of the remaining set of tables.
- For join statements with outer bring together conditions, the table with the outer join operator must come afterwards the other table in the condition in the join guild. The optimizer does not consider join orders that violate this dominion.
Choosing Execution Plans for Joins with the Cost-Based Approach
With the toll-based approach, the optimizer generates a set of execution plans based on the possible bring together orders, join operations, and available access paths. The optimizer then estimates the cost of each programme and chooses the one with the everyman price. The optimizer estimates costs in these ways:
- The cost of a nested loops operation is based on the price of reading each selected row of the outer table and each of its matching rows of the inner tabular array into retentivity. The optimizer estimates these costs using the statistics in the information dictionary.
- The toll of a sort-merge join is based largely on the cost of reading all the sources into memory and sorting them.
- The optimizer also considers other factors when determining the cost of each operation. For example:
- A smaller sort expanse size is likely to increment the price for a sort-merge bring together because sorting takes more CPU time and I/O in a smaller sort area. Sort surface area size is specified by the initialization parameter SORT_AREA_SIZE.
- A larger multiblock read count is likely to decrease the price for a sort-merge join in relation to a nested loops bring together. If a big number of sequential blocks tin can be read from disk in a unmarried I/O, an index on the inner table for the nested loops join is less probable to ameliorate functioning over a full table scan. The multiblock read count is specified by the initialization parameter DB_FILE_MULTIBLOCK_READ_COUNT.
- For join statements with outer join conditions, the table with the outer join operator must come after the other table in the condition in the join order. The optimizer does non consider join orders that violate this dominion.
With the cost-based approach, the optimizer's choice of join orders can exist overridden with the ORDERED hint. If the ORDERED hint specifies a bring together gild that violates the dominion for outer join, the optimizer ignores the hint and chooses the order. You can too override the optimizer'due south choice of join operations with hints.
Choosing Execution Plans for Joins with the Rule-Based Arroyo
With the rule-based approach, the optimizer follows these steps to choose an execution plan for a statement that joins R tables:
- The optimizer generates a prepare of R bring together orders, each with a unlike tabular array as the commencement table. The optimizer generates each potential join order using this algorithm:
- To make full each position in the join order, the optimizer chooses the tabular array with the most highly ranked available access path co-ordinate to the ranks for admission paths shown in Tabular array 23-1. The optimizer repeats this step to fill each subsequent position in the bring together order.
- For each tabular array in the bring together guild, the optimizer also chooses the operation with which to join the table to the previous table or row source in the order. The optimizer does this by "ranking" the sort-merge operation equally access path 12 and applying these rules:
- If the access path for the chosen tabular array is ranked 11 or better, the optimizer chooses a nested loops operation using the previous table or row source in the join order equally the outer table.
- If the access path for the tabular array is ranked lower than 12, and there is an equijoin condition betwixt the called table and the previous table or row source in bring together order, the optimizer chooses a sort-merge operation.
- If the access path for the chosen tabular array is ranked lower than 12, and in that location is not an equijoin status, the optimizer chooses a nested loops operation with the previous table or row source in the join lodge equally the outer table.
- The optimizer then chooses among the resulting set of execution plans. The goal of the optimizer's pick is to maximize the number of nested loops join operations in which the inner tabular array is accessed using an index scan. Since a nested loops join involves accessing the inner tabular array many times, an index on the inner table can greatly improve the performance of a nested loops join.
Commonly, the optimizer does not consider the order in which tables appear in the FROM clause when choosing an execution programme. The optimizer makes this choice by applying the following rules in order:
- The optimizer chooses the execution programme with the fewest nested-loops operations in which the inner table is accessed with a full tabular array scan.
- If there is a necktie, the optimizer chooses the execution plan with the fewest sort-merge operations.
- If in that location is still a tie, the optimizer chooses the execution programme for which the first table in the join order has the most highly ranked admission path:
- If there is a tie amidst multiple plans whose first tables are accessed by the single-column indexes access path, the optimizer chooses the plan whose kickoff table is accessed with the virtually merged indexes.
- If there is a tie amidst multiple plans whose offset tables are accessed by bounded range scans, the optimizer chooses the plan whose first table is accessed with the greatest number of leading columns of the composite index.
- If at that place is still a tie, the optimizer chooses the execution programme for which the commencement tabular array appears later in the query's FROM clause.
Views in Outer Joins
For a view that is on the correct side of an outer join, the optimzer can utilise ane of ii methods, depending on how many base tables the view accesses:
- If the view has just one base table, the optimizer tin can use view merging.
- If the view has multiple base tables, the optimizer can button the join predicate into the view.
Merging a View That Has a Unmarried Base of operations Table
A view that has one base table and is on the right side of an outer join tin be merged into the query cake of an accessing statement. (See "Merging the View'due south Query into the Statement".) View merging is possible even if an expression in the view can return a not-null value for a Zippo.
Example:
Consider the view NAME_VIEW, which concatenates get-go and terminal names from the EMP table:
CREATE VIEW name_view AS SELECT emp.firstname || emp.lastname AS emp_fullname, emp.deptno FROM emp;
and consider this outer join statement, which finds the names of all employees in London and their departments, also every bit whatsoever departments that have no employees:
SELECT dept.deptno, name_view.emp_fullname FROM emp_fullname, dept WHERE dept.deptno = name_view.deptno(+) AND dept.deptloc = 'London';
The optimizer merges the view's query into the outer bring together statement. The resulting statement looks like this:
SELECT dept.deptno, DECODE(emp.rowid, NULL, Nothing, emp.firstname || emp.lastname) FROM emp, dept WHERE dept.deptno = emp.deptno(+) AND dept.deptloc = 'London';
The transformed argument selects only the employees who piece of work in London.
Pushing the Join Predicate into a View That Has Multiple Base Tables
For a view with multiple base tables on the correct side of an outer join, the optimizer can push the join predicate into the view (run into "Pushing the Predicate into the View") if the initialization parameter OPTIMIZER_FEATURES_ENABLE is set to TRUE or the accessing query contains the PUSH_JOIN_PRED hint.
Pushing a join predicate is a cost-based transformation that can enable more efficient access path and join methods, such as transforming hash joins into nested loop joins, and full tabular array scans to index scans.
Instance:
Consider the view LONDON_EMP, which selects the employees who work in London:
CREATE VIEW london_emp Every bit SELECT emp.ename FROM emp, dept WHERE emp.deptno = dept.deptno AND dept.deptloc = 'London';
and consider this outer join statement, which finds the engineers and accountants working in London who received bonuses:
SELECT bonus.task, london_emp.ename FROM bonus, london_emp WHERE bonus.job IN ('engineer', 'auditor') AND bonus.ename = london_emp.ename(+); The optimizer pushes the outer join predicate into the view. The resulting statement (which does not conform to standard SQL syntax) looks similar this:
SELECT bonus.job, london_emp.ename FROM bonus, (SELECT emp.ename FROM emp, dept WHERE bonus.ename = london_emp.ename(+) AND emp.deptno = dept.deptno AND dept.deptloc = 'London') WHERE bonus.job IN ('engineer', 'accountant'); Optimizing Anti-Joins and Semi-Joins
An anti-bring together returns rows from the left side of the predicate for which there is no corresponding row on the right side of the predicate. That is, it returns rows that neglect to friction match (NOT IN) the subquery on the right side. For example, an anti-bring together can select a list of employees who are not in a particular set of departments:
SELECT * FROM emp WHERE deptno Not IN (SELECT deptno FROM dept WHERE loc = 'HEADQUARTERS');
The optimizer uses a nested loops algorithm for Not IN subqueries by default, unless the initialization parameter ALWAYS_ANTI_JOIN is set to MERGE or HASH and various required conditions are met that permit the transformation of the NOT IN subquery into a sort-merge or hash anti-join. You can identify a MERGE_AJ or HASH_AJ hint in the NOT IN subquery to specify which algorithm the optimizer should use.
A semi-join returns rows that match an EXISTS subquery, without duplicating rows from the left side of the predicate when multiple rows on the correct side satisfy the criteria of the subquery. For instance:
SELECT * FROM dept WHERE EXISTS (SELECT * FROM emp WHERE dept.ename = emp.ename AND emp.bonus > 5000);
In this query, only one row needs to be returned from DEPT even though many rows in EMP might lucifer the subquery. If at that place is no index on the BONUS column in EMP, a semi-bring together can be used to better query performance.
The optimizer uses a nested loops algorithm for EXISTS subqueries past default, unless the initialization parameter ALWAYS_SEMI_JOIN is set to MERGE or HASH and diverse required conditions are met. Yous can place a MERGE_SJ or HASH_SJ hint in the EXISTS subquery to specify which algorithm the optimizer should use.
Optimizing "Star" Queries
One blazon of information warehouse design centers around what is known every bit a "star" schema, which is characterized by one or more than very large fact tables that incorporate the primary information in the information warehouse and a number of much smaller dimension tables (or "lookup" tables), each of which contains information about the entries for a particular attribute in the fact table.
A star query is a join between a fact table and a number of lookup tables. Each lookup table is joined to the fact tabular array using a primary-cardinal to foreign-primal join, simply the lookup tables are not joined to each other.
Cost-based optimization recognizes star queries and generates efficient execution plans for them. (Star queries are not recognized by rule-based optimization.)
A typical fact table contains keys and measures. For instance, a simple fact tabular array might comprise the mensurate Sales, and keys Time, Product, and Market place. In this case there would be corresponding dimension tables for Time, Product, and Market. The Product dimension table, for example, would typically contain information about each product number that appears in the fact table.
A star join is a primary-fundamental to foreign-key bring together of the dimension tables to a fact table. The fact table normally has a concatenated alphabetize on the fundamental columns to facilitate this blazon of join.
See Oracle8i Tuning for more than information about dimensions and data warehouses.
Star Query Instance
This section discusses star queries with reference to the following case:
SELECT SUM(dollars) FROM facts, time, product, market WHERE market.stat = 'New York' AND product.brand = 'MyBrand' AND fourth dimension.year = 1995 AND time.calendar month = 'March' /* Joins*/ AND time.key = facts.tkey AND product.pkey = facts.pkey AND market.mkey = facts.mkey;
Tuning Star Queries
To execute star queries efficiently, you must use cost-based optimization. Begin by gathering statistics (using the DBMS_STATS package or the Analyze command) for each of the tables accessed past the query.
Indexing
In the example higher up, you would construct a concatenated alphabetize on the columns tkey, pkey, and mkey. The lodge of the columns in the index is critical to performance. the columns in the alphabetize should take advantage of whatever ordering of the data. If rows are added to the large tabular array in time order, and then tkey should be the get-go cardinal in the index. When the information is a static excerpt from another database, information technology is worthwhile to sort the data on the fundamental columns before loading it.
If all queries specify predicates on each of the modest tables, a single concatenated index suffices. If queries that omit leading columns of the concatenated index are frequent, additional indexes may be useful. In this example, if at that place are frequent queries that omit the time table, an index on pkey and mkey can be added.
Hints
Usually, if you clarify the tables the optimizer volition choose an efficient star plan. You tin can also use hints to improve the plan. The almost precise method is to order the tables in the FROM clause in the order of the keys in the index, with the large tabular array last. And so apply the post-obit hints:
/*+ ORDERED USE_NL(facts) INDEX(facts fact_concat) */
A more than general method is to use the STAR hint /*+ STAR */.
Extended Star Schemas
Each of the pocket-sized tables can be replaced by a join of several smaller tables. For example, the product table could be normalized into brand and manufacturer tables. Normalization of all of the small tables can cause functioning problems. One problem is caused by the increased number of permutations that the optimizer must consider. The other trouble is the effect of multiple executions of the small table joins.
Y'all can solve both of these problems by using denormalized views. For example:
CREATE VIEW prodview Equally SELECT /*+ NO_MERGE */ * FROM brands, mfgrs WHERE brands.mfkey = mfgrs.mfkey;
This hint reduces the optimizer's search infinite and causes caching of the result of the view.
Star Transformation
The star transformation is a cost-based query transformation aimed at executing star queries efficiently. Whereas the star optimization works well for schemas with a minor number of dimensions and dense fact tables, the star transformation may be considered as an alternative if whatever of the following holds true:
- The number of dimensions is large.
- The fact table is sparse.
- There are queries where not all dimension tables have constraining predicates.
The star transformation does not rely on computing a Cartesian product of the dimension tables, which makes information technology better suited for cases where fact table sparsity and/or a large number of dimensions would atomic number 82 to a big Cartesian production with few rows having bodily matches in the fact tabular array. In addition, rather than relying on concatenated indexes, the star transformation is based on combining bitmap indexes on private fact table columns.
The transformation can thus choose to combine indexes corresponding precisely to the constrained dimensions. There is no demand to create many concatenated indexes where the dissimilar column orders match unlike patterns of constrained dimensions in different queries.
Attention:
Bitmap indexes are available simply if you accept purchased the Oracle8i Enterprise Edition. In Oracle8i, bitmap indexes are not available and star query processing uses B*-tree indexes. In the Oracle8i Enterprise Edition, the parallel bitmap alphabetize join algorithm is besides bachelor for star query processing.
Come across Getting to Know Oracle8i for more than information about the features available in Oracle8i and Oracle8i Enterprise Edition.
The star transformation works by generating new subqueries that tin can be used to drive a bitmap alphabetize admission path for the fact table.
Consider a unproblematic case with three dimension tables, "d1", "d2", and "d3", and a fact tabular array, "fact". The following query:
EXPLAIN Program FOR SELECT * FROM fact, d1, d2, d3 WHERE fact.c1 = d1.c1 AND fact.c2 = d2.c1 AND fact.c3 = d3.c1 AND d1.c2 IN (1, two, 3, four) AND d2.c2 < 100 AND d3.c2 = 35
gets transformed by calculation three subqueries:
SELECT * FROM fact, d1, d2, d3 WHERE fact.c1 = d1.c1 AND fact.c2 = d2.c1 AND fact.c3 = d3.c3 AND d1.c2 IN (1, 2, 3, four) AND d2.c2 < 100 AND d3.c2 = 35 AND fact.c1 IN (SELECT d1.c1 FROM d1 WHERE d1.c2 IN (1, 2, 3, four)) AND fact.c2 IN (select d2.c1 FROM d2 WHERE d2.c2 < 100) AND fact.c3 IN (SELECT d3.c1 FROM d3 WHERE d3.c2 = 35)
In addition, if it is cost constructive, one or more of the subqueries may exist further optimized by storing its results in a temporary tabular array. Then the subquery is replaced with a subquery on the temporary tabular array. For instance, if the showtime subquery to a higher place was selected for this temporary tabular array transformation, a temporary table named ORA_TEMP_1_123 is created and filled with the results of the subquery:
SELECT d1.c1 from d1 where d1.c2 in (1, ii, iii, 4)
The fully transformed query is now:
SELECT * FROM fact, ORA_TEMP_1_123, d2, d3 WHERE fact.c1 = ORA_TEMP_1_123.c1 AND fact.c2 = d2.c1 and fact.c3 = d3.c1 AND ORA_TEMP_1_123.c1 IN (1, ii, iii, 4) AND d2.c2 < 100 AND d3.c2 = 35 AND fact.c1 IN (SELECT ORA_TEMP_1_123.c1 FROM ORA_TEMP_1_123) AND fact.c2 IN (SELECT d2.c1 FROM d2 WHERE d2.c2 < 100) AND fact.c3 IN (SELECT d3.c1 FROM d3 WHERE d3.c2 = 35)
Given that there are bitmap indexes on fact.c1, fact.c2, and fact.c3, the newly generated subqueries can exist used to drive a bitmap index access path in the post-obit way.
For each value of c1 that is retrieved from the first subquery, the bitmap for that value is retrieved from the index on fact.c1 and these bitmaps are merged. The effect is a bitmap for precisely those rows in fact that match the condition on d1 in the subquery WHERE clause.
Similarly, the values from the 2nd subquery are used together with the bitmap index on fact.c2 to produce a merged bitmap corresponding to the rows in fact that friction match the status on d2 in the second subquery. The same operations apply to the third subquery. The three merged bitmaps can and so be ANDed, resulting in a bitmap corresponding to those rows in fact that meet the weather condition in all 3 subqueries simultaneously.
This bitmap can exist used to access fact and call back the relevant rows. These are then joined to d1, d2, and d3 to produce the answer to the query. No Cartesian product is needed.
Execution Plan
The following execution programme might outcome from the query to a higher place:
SELECT STATEMENT TEMP TABLE GENERATION TEMP TABLE GENERATION HASH Join HASH Join HASH Bring together TABLE Access FACT BY INDEX ROWID BITMAP CONVERSION TO ROWIDS BITMAP AND BITMAP MERGE BITMAP Cardinal ITERATION TABLE Admission D3 FULL BITMAP Index FACT_C3 RANGE Browse BITMAP MERGE BITMAP Cardinal ITERATION Tabular array Access ORA_TEMP_1_123 FULL BITMAP Alphabetize FACT_C1 RANGE Browse BITMAP MERGE BITMAP KEY ITERATION TABLE Admission D2 Full BITMAP Index FACT_C2 RANGE SCAN Tabular array Access ORA_TEMP_1_123 Total TABLE ACCESS D2 FULL TABLE Access D3 FULL
In this plan the fact tabular array is accessed through a bitmap access path based on a bitmap AND of three merged bitmaps. The three bitmaps are generated by the BITMAP MERGE row source being fed bitmaps from row source trees underneath it. Each such row source tree consists of a BITMAP Central ITERATION row source which fetches values from the subquery row source tree, which in this example is merely a full table access, and for each such value retrieves the bitmap from the bitmap index. After the relevant fact tabular array rows have been retrieved using this access path, they are joined with the dimension tables and temporary tables to produce the answer to the query. The two rows in the execution plan labelled "TEMP Table GENERATION" comprise the SQL commands used to create and populate the temporary table. These commands are in the OTHER column of the execution plan, which was non displayed in the example above.
The star transformation is a cost-based transformation in the following sense. The optimizer generates and saves the best programme it can produce without the transformation. If the transformation is enabled, the optimizer then tries to apply information technology to the query and if applicable, generates the all-time programme using the transformed query. Based on a comparison of the cost estimates betwixt the best plans for the two versions of the query, the optimizer will so decide whether to use the best programme for the transformed or untransformed version.
If the query requires accessing a big percentage of the rows in the fact tabular array, it may well be better to use a full table browse and not apply the tranformations. However, if the constraining predicates on the dimension tables are sufficiently selective that only a small portion of the fact tabular array needs to be retrieved, the plan based on the transformation volition probably be superior.
Note that the optimizer will generate a subquery for a dimension tabular array but if information technology decides that it is reasonable to exercise so based on a number of criteria. At that place is no guarantee that subqueries will be generated for all dimension tables. The optimizer may also decide, based on the properties of the tables and the query, that the transformation does not merit existence practical to a particular query. In this case the best regular plan will be used.
Using Star Transformation
You tin can enable star transformation by setting the value of the initialization parameter STAR_TRANSFORMATION_ENABLED to TRUE. To use star transformation without temporary tables, set the value of the parameter to TEMP_DISABLE. Use the STAR_TRANSFORMATION hint to brand the optimizer use the best programme in which the transformation has been used.
Restrictions on Star Transformation
Star transformation is non supported for tables with any of the following characteristics:
- tables with a table hint that is incompatible with a bitmap access path
- tables with as well few bitmap indexes (there must be a bitmap index on a fact table column for the optimizer to consider generating a subquery for information technology)
- remote tables (notwithstanding, remote dimension tables are allowed in the subqueries that are generated)
- anti-joined tables
- tables that are already used every bit a dimension tabular array in a subquery
- tables that are actually unmerged views, which are not view partitions
- tables that have a proficient single-tabular array access path
- tables that are also small for the transformation to be worthwhile.
In addition, temporary tables will non be used past star transformation under the following conditions:
- the database is in read simply manner
- the star query is role of a transaction that is in serializable mode.
Source: https://docs.oracle.com/cd/F49540_01/DOC/server.815/a67781/c20c_joi.htm
0 Response to "what kind of joins do you use to join large tables in oracle 11g"
Post a Comment